2020 was quite a year for SEO news, from new ranking factors being announced to new technologies disrupting how we think about content, pagespeed and automation. As usual, we saw our share of core algorithm updates, and this year they came with a special surprise mix of indexing bugs. The COVID-19 pandemic also led to some changes in search behavior and trends, with a particular impact for more directly affected industries like travel, weddings, real estate, health, and remote working services.
Google has continued to double down on page speed, mobile and user experience metrics. Continuation of mobile-first indexing for all websites, Core Web Vitals and a new Page Experience algorithm are all coming in 2021, so we’ve seen a lot of early announcements and discussion in preparation for this rollout.
We’ve also seen a lot of interesting case studies and SEO split testing results come out this year, and automation has been a hot topic both for us internally (finding new ways to automate the boring stuff!) and in the industry as a whole, with new AI tools offering automation for previously manual work like content generation. And data accessibility and privacy concerns continue to raise new questions and problems to solve, as well as regulations and restrictions that limit what data we have access to (for example, the news that Google Chrome plans to kill browser UA strings).
All in all, 2020 saw a lot of interesting insights and discussion within the search industry as a whole, as well as here at TightShip headquarters. Here are the stories we’ve been talking about!
Q1 2020: core algo update + other news
- Jan – January 2020 core update (Google news)
- Jan – Botify partners with Bing to bypass XML Sitemaps and submit URLs directly to search engines (tool news)
- Jan – Sites with featured snippets no longer also appear in page 1 results (Google news)
- Jan – SERP UI changes (industry updates):

- Feb – Can you trust SEO tools for B2B keyword research? (discussion)
- Mar – John Mueller discusses how Google views JS-only redirects (Google news)
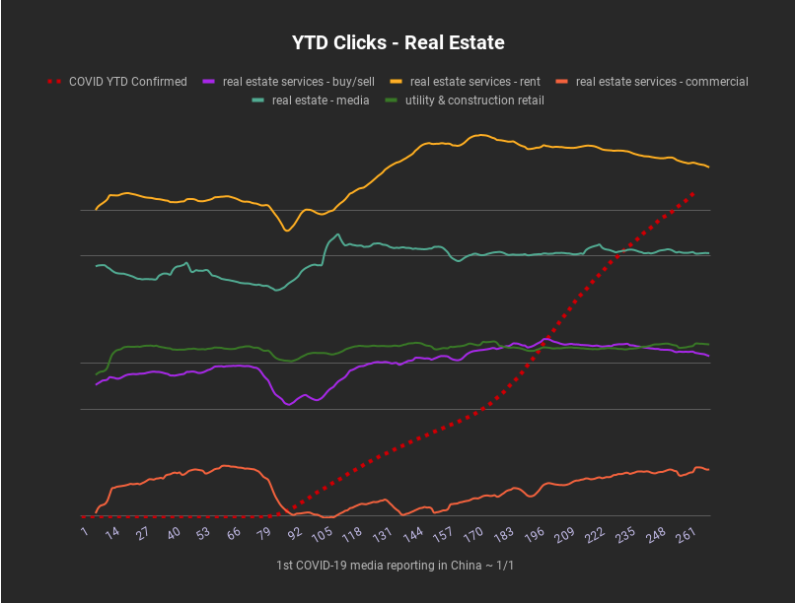
- Mar – Tight Ship built a custom Botify API connector and did some cross-customer COVID trends reporting in partnership with Botify.com (industry updates):
Q2 2020: core algo update + other news
- Apr – FAQs for branded SERPs (discussion):
- Question: Will Google include FAQ results on a branded SERP with sitelinks if schema is added for questions and answers?
- May – May 2020 core update (Google news)
- May – the “Google Page Experience Algorithm” to become a ranking factor in 2021 (Google news)
- Jun – Google has indexing issues (Google news)
- Jun – text highlighting rolls out for featured snippets (industry news)
- Jun – Google Page Experience scores will use AMP version (discussion)
Thoughts from the TightShip team:
Mike: “It’s interesting that they use the mobile version (not AMP) for indexing, but then they use UX data from the AMP version, and Desktop they just serve to Desktop users – sounds like the Desktop experience doesn’t factor at all? (In the mobile first scenario JM describes)”
Ben: “In my opinion, mobile-first continues to be a big joke — and has been responsible for many of the crawl/indexation problems they’ve had over the last couple years.”
Q3 2020: mobile first indexing update + other news
- Jul – mobile first indexing rolling out in Mar 2021 – later than expected (Google news)
- Jul – Google deprecates structured data testing tool (tool news)
- Recommended to use Rich Results Tester moving forward
- Jul – Regex filter support coming to GSC performance reports (tool news)
- Jul – Ranking search results may be based on Information Gain Scores (Google news)
- Jul – Special “image” in SERPs for AMP web stories (industry news)
- Jul – Googlebot is able to add products to your shopping cart (Google news)
- Jul – Google: CLS is measured through the entire lifecycle of the page (best practice)
- Jul – web stories are coming to WordPress (tool news)
- Jul – Chrome wants to kill browser UA strings (discussion)
Thoughts from the TightShip team:
Ben: “What’s going to happen to log data or dynamic rendering when chrome kills the UA string? Initial thoughts:
- Hopefully Google will still pass user-agent for the headless browser they use for Googlebot.
- No more measuring organic visits (or any at all) via Log files.
- No more dynamic rendering (custom content) via user-agent detection. Mike: “I’d bet on them continuing to crawl with a Googlebot UA for quite a while.”
Twitter thread with further discussion / clarification (link)
Ben: “Is it me or does this mean it’s critically important for Googlebot to have the ability to retrieve assets via the server-side HTML request?”
Mike: “Yes the implication is that Googlebot gets and caches it all at once and then does the loading with WRS later.”
Ben: “One interesting note is how cached content can easily get outdated so we should be looking at whether Google’s render is current and following best practices for caching.”
Mike: “How will we know how long until WRS? That would probably be a different delay depending on resources/demand so no one measurement is representative even if we did test it. Best practices for caching are worth reviewing but I expect most high-traffic JS heavy sites are already fingerprinting resources properly.”
- Jul – Google pruning FAQs / how to schema rich results (industry news)
- Aug – Google verifies that keywords in URLs are not important (Google news)
- Aug – rankings chatter but no major update announced – apparently a glitch (Google news)
- Aug – Cloudflare announces low-latency solution for updating HTML on the fly (tool news)
- Aug – Search Console uses CrUX RUM data to check Core Web Vitals metrics – it doesn’t need Googlebot (Google news)
- Sep – Google announces options for retailers to control how their crawled product info appears on Google (Google news)
- Sep – security issue false positives in GSC (tool news)
- Sep – STAT rolls out GDS data connectors (tool news)
- Sep – Google Ads API is now available to all (Google news)
Q4 2020: core algo update + other news
- Oct – Google to identify individual passages of a webpage to understand relevance to a given search (Google news)
- Oct – GMB SAB and Virtual Offices Guidelines updated (Google news)
- Oct – Google indexing bug – progress report (Google news)
- Oct – Cookie consent banners impacting CLS (industry news)
- Oct – GSC might show URL fragment identifiers (tool news)
- Oct – Submitting URLs does not lead to Google reprocessing sitemaps (Google news)
- Oct – SERP volatility, rankings chatter – likely due to indexing issues (Google news)
- Oct – Request Indexing feature in URL Inspection tool disabled temporarily (tool news)
- Nov – Core Web Vitals will be added to the algorithm in May 2021
- Nov – Google: BERT now used on almost every English query
- Nov – Goodbye Google Webmasters, hello Google Search Central (tool news)
- Nov – Google updates Remove Outdated Content tool (tool news)
- Dec – December 2020 Core Update (Google news)
- Dec – Structured Data Testing Tool is being migrated to Schema.org and being “refocused.”
Tips and tricks (Tightship)
Some cool things we learned to make our work easier.
- How to crawl Wayback Machine to understand when content was added to a site (Mike)
- Crawl Wayback Machine with Screaming Frog and scrape the first saved date (the first time Wayback Machine stored a snapshot) for a list of URLs.
- Handy for figuring out when client competitors added specific pages (it will obviously miss URL changes and cases where the page was not crawlable by the Wayback Machine for whatever reason but better than nothing).
- This CSS selector works currently:
#react-wayback-search > div.captures-range-info > span > a:nth-child(1) - URLs to crawl are just https://web.archive.org/web/*/{pageurl}
- (e.g. https://web.archive.org/web/*/https://www.domain.com/page-title/) (note: JS rendering required)
- Crawl Wayback Machine with Screaming Frog and scrape the first saved date (the first time Wayback Machine stored a snapshot) for a list of URLs.
- How to filter uRLs for non-ASCII characters in Botify reports using REGEX (Ben)
- You can remove non-ASCII characters using this REGEX:
[^\x00-\x7F]+
- You can remove non-ASCII characters using this REGEX:
- How to handle Screaming Frog data pulls with a lot of blank columns and consolidate “tags” (Mike)
- Ever scrape a bunch of pages with Screaming Frog and end up with a number of columns (equal to the maximum number of occurrences for your extractor), often blank, with no easy way to consolidate them?
- Use JOIN to merge them all with a separator, and within that use FILTER to exclude the blank columns.
e.g. =JOIN(",",FILTER(D18:N18,NOT(ISBLANK(D18:N18)))) - One use case for this is to scrape “tags” (related search pages) from image URLs. Consolidating them in one column makes it easier to create filters, use QUERY in another sheet to pull all URLs matching a given tag, etc.
- Use JOIN to merge them all with a separator, and within that use FILTER to exclude the blank columns.
- Ever scrape a bunch of pages with Screaming Frog and end up with a number of columns (equal to the maximum number of occurrences for your extractor), often blank, with no easy way to consolidate them?

- Handy terminal command for downloading files from a URL list (Ben).
xargs -n 1 curl -O < files.txt- For GZip files, the “Open Multiple URLs” Chrome add-on will automatically download them as well (Chrome downloads any GZip URL you open).
- How to create a pagespeed Issue breakdown by pagetype using DataStudio visual themes:

Insights we found useful
Interesting ideas and observations from experts we follow.
- Experiment: Opting out of featured snippets led to 12% traffic loss (Cyrus Shepard)
- Why recovery from a core algorithm update impact can take until the next update (Will Critchlow)
- Best practice: structured data linking for multiple items on a page (SER)
- Google Search Console data holes (SER)
- Multi-variate regressions and why SEOs are doing it wrong (Victor Pan)
- Split test: adding trust-building elements above the fold led to 7-10% uplift in organic traffic (SearchPilot)
- Response times insights: 10 seconds is the limit for keeping user’s attention (NNGroup)
- Googling for gut symptoms predicts COVID hotspots (Bloomberg) – a great example of how search volume research can be used to understand “real world” trends
- Split test: re-ordering HTML so that primary page content occurs before sidebar content in source code yields +16% lift in organic sessions (SearchPilot)
- JS redirects do not pass “original” referral data (Receptional)
- Google crawl budget shared between organic and ads (SER)
- Will OpenAI’s pricing plan for GPT-3 be able to turn the massive AI langage model into a profitable business?
- Is SEO a dying industry? (Tim Brown) …spoiler: SEO budgets are actually growing Y/Y
2020 Tightship hot takes
Who doesn’t love a little controversial opinion from time to time?
- Google’s lizard brain is alive and well in terms of backlinks
- Here is an example of a website recently ranking well with spammy backlinks. The majority of these are links from Russia. They also redirected an old political site with strong links from NYT and WaPo to the domain.

- Communication style and organizational context are an essential element of SEO pagespeed recommendations
- Pagespeed is a complex topic and a lot of SEOs flag surface-level metric changes without considering the details of the existing implementation and/or internal politics and historical context.
- Mike’s take: “It’s a “tread carefully” area because most dev teams have some best practices in place and have done a good amount of work on it, so as an SEO you can easily look out of your depth if you come in with a lot of broad recommendations and lack of organizational context. In this respect, Pagespeed Insights may have done more harm than good over the years, because the score is too simple (faster sites can score worse than slower sites). They’re getting better now though, and new metrics like core web vitals are a step in the right direction.”
- Jake’s take: “Losing credibility with the devs implementing your recommendations is not a good thing. You can also inadvertently throw the dev team under the bus if more senior leaders are part of these conversations, and don’t have the technical knowledge to understand the devs have already done what they can on the pages.”
- Pagespeed is a complex topic and a lot of SEOs flag surface-level metric changes without considering the details of the existing implementation and/or internal politics and historical context.
- Should we be redirecting outdated but indexed pages with backlinks? Maybe not.
- Mike’s take: “If we acknowledge that Google won’t pass PageRank from specific URLs to a category/homepage (as Mueller suggests here they’ll treat that as a soft 404), then when we encounter a bunch of old pages in the index with backlinks, redirecting them all to some root is a waste of time.
- If they’re not currently treated as soft 404s, then we may be better off leaving them indexed – if they link at all back to the core site, that PageRank is still flowing, whereas if we redirect and Google treats as a soft 404, no PageRank flow. Keep live or spend extra time finding the ideal redirect source may be the better options of bulk redirects to category
- For example: a bunch of orphan pages hanging in the index with external links, but a lot of them are press/blog pages without a good alternative. Might just say “let them sit unless the business wants them offline”.”
- Mike’s take: “If we acknowledge that Google won’t pass PageRank from specific URLs to a category/homepage (as Mueller suggests here they’ll treat that as a soft 404), then when we encounter a bunch of old pages in the index with backlinks, redirecting them all to some root is a waste of time.
- Is technical SEO a 100% solved problem?
- Jono Alderson recently tweeted that “Technical SEO is a 100% solved problem“.
- Ben’s take: “There’s truth to that – but not sure you can say technical SEO is 100% solved if you’re working with humans to implement the solutions. Also there are a handful of new problems to solve every year. Then if you add reporting and proving value for Technical SEO, very not solved.”
- Mike’s take: “I’d put it at 90% solved, so many mess-ups still happening at scale. But it’s rare you solve a technical issue and see some pronounced impact on traffic. Lots of little edge cases, screw-ups that take too long to fix, etc. It’s worth saving 2% of organic traffic to a pagetype at a time, just doesn’t make for a dramatic change on its own.”
- Jono Alderson recently tweeted that “Technical SEO is a 100% solved problem“.
Tools and Tool Features We Liked in 2020
- The new SEMrush Keyword Gap tool looks like it’s easier to work with, with better pre-filtered data.

- GPT-3 NLG: using AI for SEO copy (SearchPilot article)
- ScreamingFrog:
- Searchmetrics: recommended for opportunity assessment and competitive analysis – visibility scores more reliable than SEMRush.
- For PAA (People Also Ask) data, featured sites or “related searches” from Google SERPs:
- Ahrefs’ SEO forecasting tool looks good.
- SEMRush’s Impact Hero feature looks like it could automate buyer journey stage assignment for landing pages, which is a pain to do manually.
- Google Tables: we’ve been playing around with Tables a little as an alternative to Asana / other PM tools. Seems like it’d be fairly straightforward to integrate with other apps based on table interactions.
- Thruuu: looks like a decent SERP scraping tool. A little limited in only being able to put in one keyword but still some helpful insights.